Data Science#
An introduction to data science with no coding involved with Blue Code#

Let's discover
Data Science for Everyone in less than 5 minutes with Blue Code.
Getting Started#
Here is a diagram showing some of the common disciplines that a data scientist may draw upon. A data scientist’s level of experience and knowledge in each, often varies along a scale ranging from beginner, to proficient, and to expert, in the ideal case.
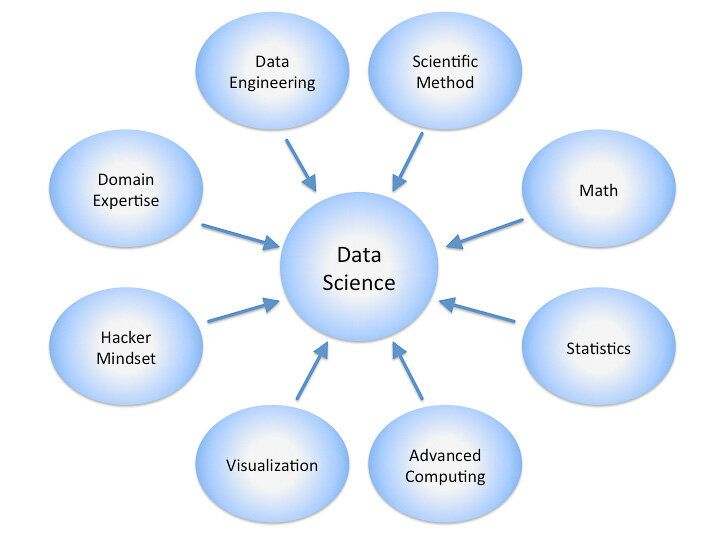
The Pillars of Data Science Expertise
While data scientists often come from many different educational and work experience backgrounds, most should be strong in, or in an ideal case be experts in four fundamental areas. In no particular order of priority or importance, these are:
Business/Domain
Mathematics (includes statistics and probability)
Computer science (e.g., software/data architecture and engineering)
Communication (both written and verbal)
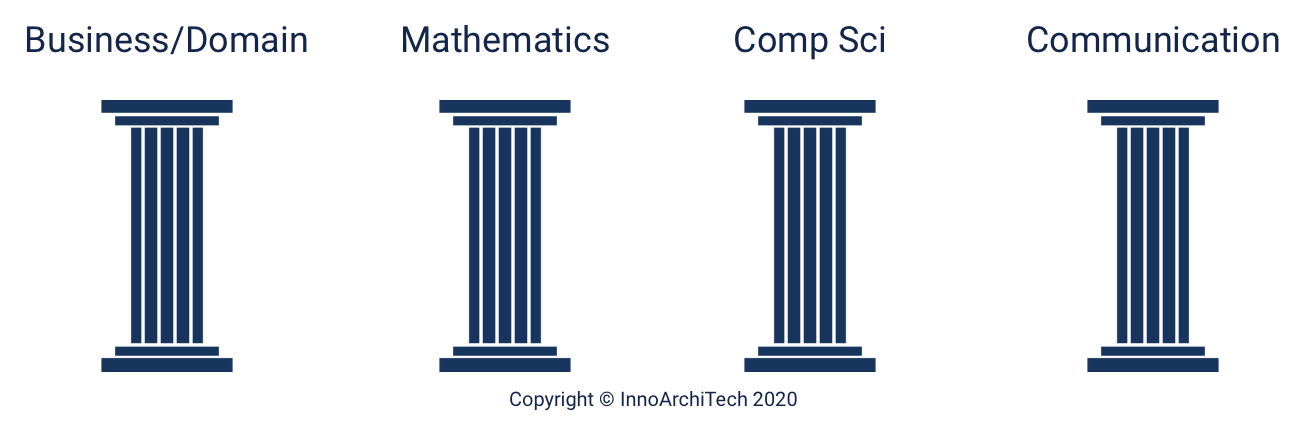
Based on these pillars, data scientist definition is a person who should be able to leverage existing data sources, and create new ones as needed in order to extract meaningful information and actionable insights. A data scientist does this through business domain expertise, effective communication and results interpretation, and utilization of any and all relevant statistical techniques, programming languages, software packages and libraries, and data infrastructure. The insights that data scientists uncover should be used to drive business decisions and take actions intended to achieve business goals.
Data Science Goals and Deliverables#
Prediction (predict a value based on inputs)
Classification (e.g., spam or not spam)
Recommendations (e.g., Amazon and Netflix recommendations)
Pattern detection and grouping (e.g., classification without known classes)
Anomaly detection (e.g., fraud detection)
Recognition (image, text, audio, video, facial, …)
Actionable insights (via dashboards, reports, visualizations, …)
Automated processes and decision-making (e.g., credit card approval)
Scoring and ranking (e.g., FICO score)
Segmentation (e.g., demographic-based marketing)
Optimization (e.g., risk management)
Forecasts (e.g., sales and revenue)
Data Scientists vs. Data Analysts vs. Data Engineers#
As mentioned, often the data scientist role is confused with other similar roles. The two main ones are data analysts and data engineers, both quite different from each other, and from data science as well.
Let’s explore both of these roles in more detail.
Data analysts share many of the same skills and responsibilities as a data scientist, and sometimes have a similar educational background as well. Some of these shared skills include the ability to:
Access and query (e.g., SQL) different data sources
Process and clean data
Summarize data
Understand and use some statistics and mathematical techniques
Prepare data visualizations and reports
Some of the key differences however, are that data analysts typically are not computer programmers, nor responsible for statistical modeling, machine learning, and many of the other steps outlined in the data science process above.
The tools used are usually different as well. Data analysts often use tools for analysis and business intelligence like Microsoft Excel (visualization, pivot tables, …), Tableau, SAS, SAP, and Qlik.
Analysts sometimes perform data mining and modeling tasks, but tend to use visual platforms such as IBM SPSS Modeler, Rapid Miner, SAS, and KNIME. Data scientists, on the other hand, perform these same tasks usually with tools such as R and Python, combined with relevant libraries for the language(s) being used.
Lastly, data analysts tend to differ significantly in their interactions with top business managers and executives. Data analysts are often given questions and goals from the top down, perform the analysis, and then report their findings.
however, tend to generate the questions themselves, driven by knowing which business goals are most important and how the data can be used to achieve certain goals. In addition, data scientists typically leverage programming with specialized software packages and employ much more advanced statistics, analytics, and modeling techniques.
Data engineers are becoming more important in the age of big data, and can be thought of as a type of data architect. They are less concerned with statistics, analytics, and modeling as their data scientist/analyst counterparts, and are much more concerned with data architecture, computing and data storage infrastructure, data flow, and so on.
The data used by data scientists and big data applications often come from multiple sources, and must be extracted, moved, transformed, integrated, and stored (e.g., ETL/ELT) in a way that’s optimized for analytics, business intelligence, and modeling.
Data engineers are therefore responsible for data architecture, and for setting up the required infrastructure. As such, they need to be competent programmers with skills very similar to someone in a DevOps role, and with strong data query writing skills as well.
Another key aspect of this role is database design (RDBMS, NoSQL, and NewSQL), data warehousing, and setting up a data lake. This means that they must be very familiar with many of the available database technologies and management systems, including those associated with big data (e.g., Hadoop, Redshift, Snowflake, S3, and Cassandra).
Lastly, data engineers also typically address non-functional infrastructure requirements such as scalability, reliability, durability, availability, backups, and so on.
We’ll finish with an overview of some of the typical tools in the data scientist’s proverbial toolbox.
Since computer programming is a large component, data scientists must be proficient with programming languages such as Python, R, SQL, Java, Julia, and Scala. Usually it’s not necessary to be an expert programmer in all of these, but Python or R, and SQL are definitely key.
For statistics, mathematics, algorithms, modeling, and data visualization, data scientists usually use pre-existing packages and libraries where possible. Some of the more popular Python-based ones include Scikit-learn, TensorFlow, PyTorch, Pandas, Numpy, and Matplotlib.
For reproducible research and reporting, data scientists commonly use notebooks and frameworks such as Jupyter and JupyterLab. These are very powerful in that the code and data can be delivered along with key results so that anyone can perform the same analysis, and build on it if desired.
More and more these days, data scientists should be able to utilize tools and technologies associated with big data as well. Some of the most popular examples include Hadoop, Spark, Kafka, Hive, Pig, Drill, Presto, and Mahout.
Data scientists should also know how to access and query many of the top RDBMS, NoSQL, and NewSQL database management systems. Some of the most common are MySQL, PostgreSQL, Redshift, Snowflake, MongoDB, Redis, Hadoop, and HBase.
Finally, cloud computing and cloud-based services and APIs are an important part of the data scientists toolbox, particularly in terms of data storage and access, machine learning, and artificial intelligence (AI). The most common cloud service providers are Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Compute (GCP). DevOps and DataOps orchestration and deployment increasingly involves container-based technologies such as Docker and Kubernetes (K8s), along with Infrastructure as Code (IaC) tools such as Terraform.
Business Intelligence (BI) vs. Data Science#
Business Intelligence (BI) basically analyzes the previous data to find hindsight and insight to describe business trends. Here BI enables you to take data from external and internal sources, prepare it, run queries on it and create dashboards to answer questions like quarterly revenue analysis or business problems. BI can evaluate the impact of certain events in the near future. Data Science is a more forward-looking approach, an exploratory way with the focus on analyzing the past or current data and predicting the future outcomes with the aim of making informed decisions. It answers the open-ended questions as to “what” and “how” events occur.
Start your Data Science Journey with a free BootCamp here..#
Click on me to download your Data Science Book..
Click on me to Continue Learning Data science